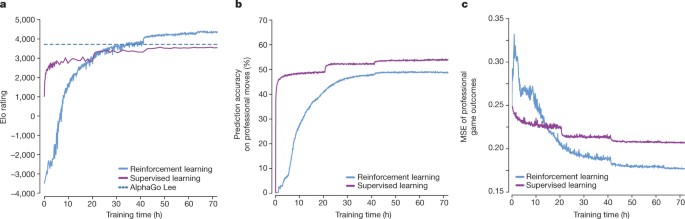
Single-Player Alpha Zero examples - RLlib - Ray
Por um escritor misterioso
Descrição
How severe does this issue affect your experience of using Ray? Medium: It contributes to significant difficulty to complete my task, but I can work around it. I would like to take a look at some examples of using the Single-Player Alpha Zero algorithm. The link of the documentation is broken. Also if anyone have done something with it and is willing share, I will be thankfull.
An Overview of Ray - Learning Ray - Flexible Distributed Python
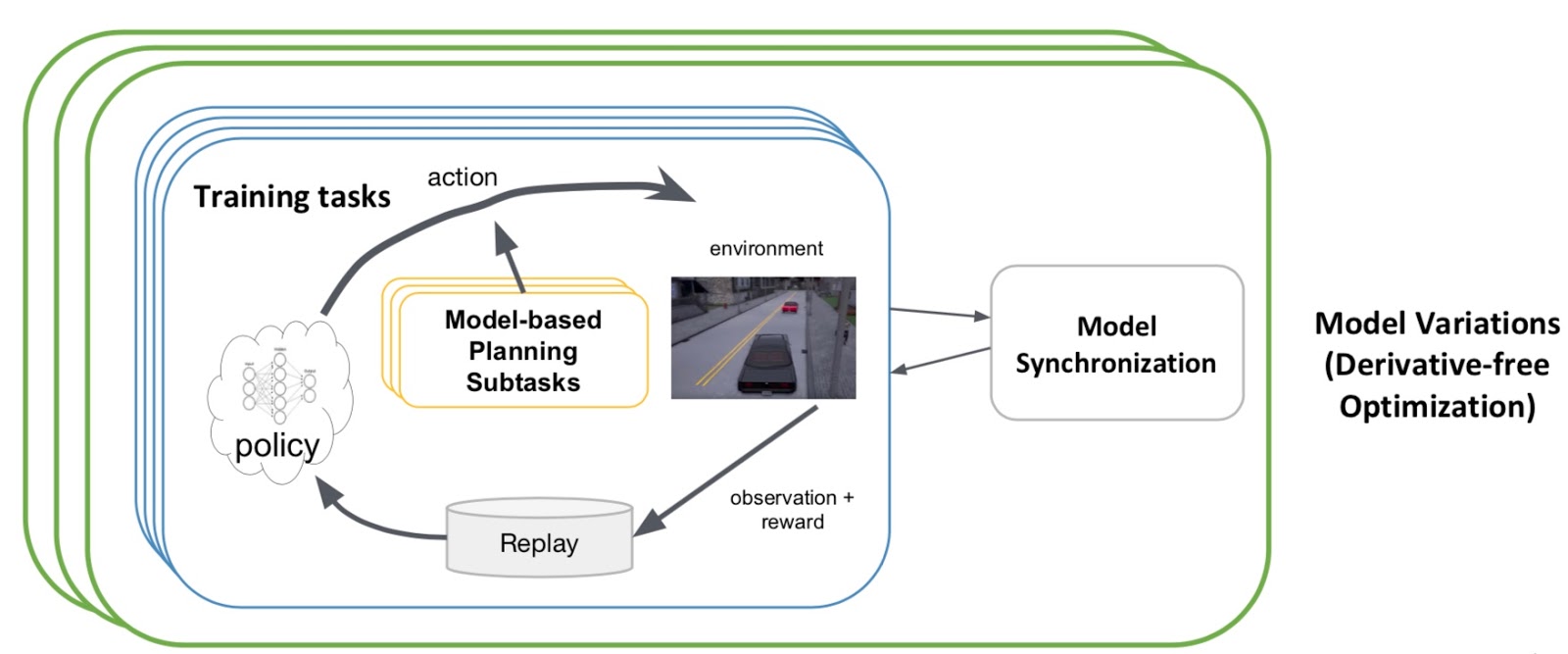
Introducing RLlib: A composable and scalable reinforcement

Algorithms — Ray 2.8.1
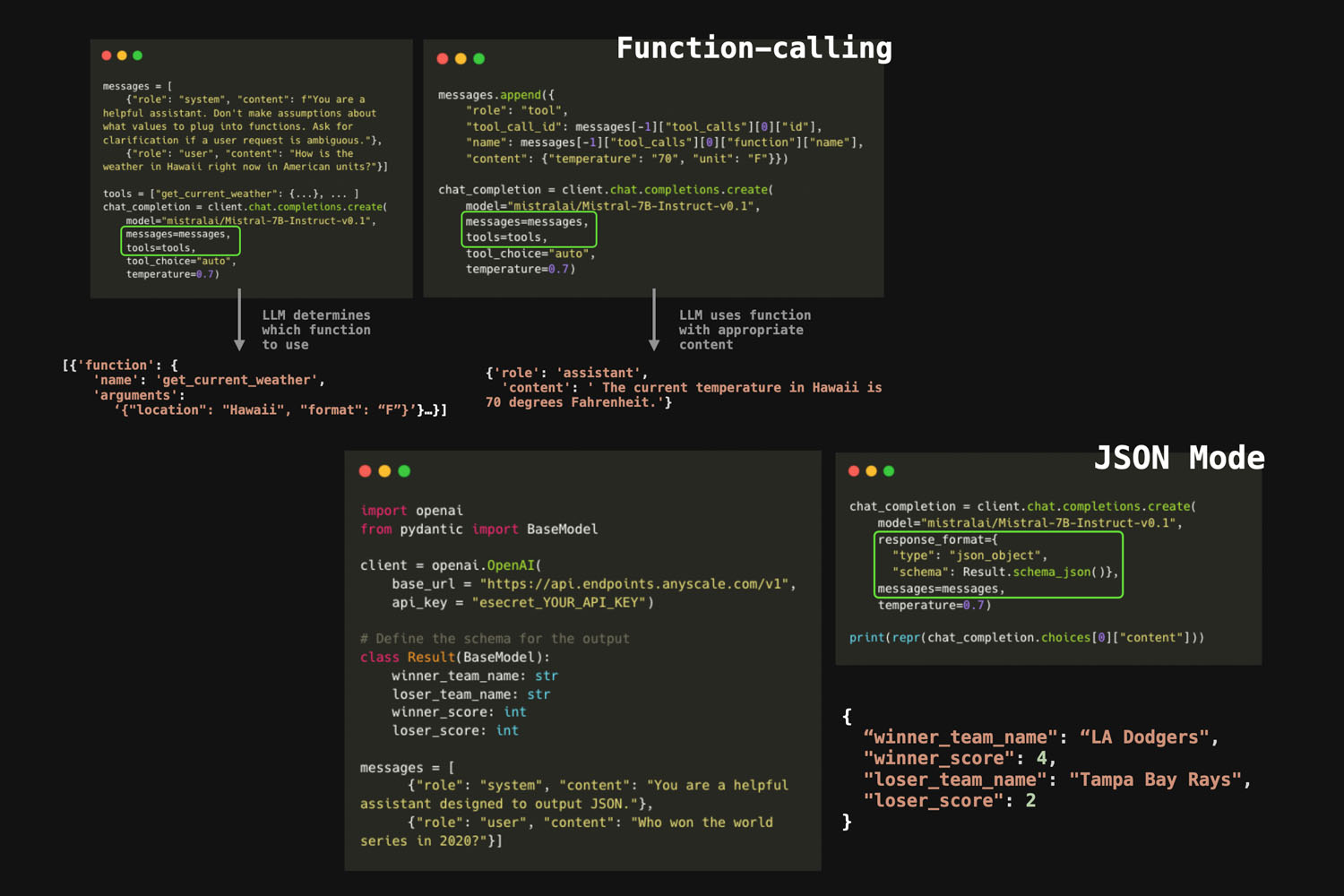
Announcing Ray 2.4.0: Infrastructure for LLM training, tuning

Announcing Ray support on Databricks and Apache Spark Clusters
llm-applications/datasets/routing-dataset-train.jsonl at main

Ray RLlib: A Composable and Scalable Reinforcement Learning
Hands-on Reinforcement Learning :: DIAMBRA Docs

Single-Player Alpha Zero examples - RLlib - Ray

RLlib: Industry-Grade Reinforcement Learning — Ray 2.8.1

Ray 2.5 Training & Serving for LLMs, Multi-GPU Training & More
de
por adulto (o preço varia de acordo com o tamanho do grupo)