PDF) Incorporating representation learning and multihead attention
Por um escritor misterioso
Descrição

Mockingjay: Unsupervised Speech Representation Learning with Deep Bidirectional Transformer Encoders – arXiv Vanity
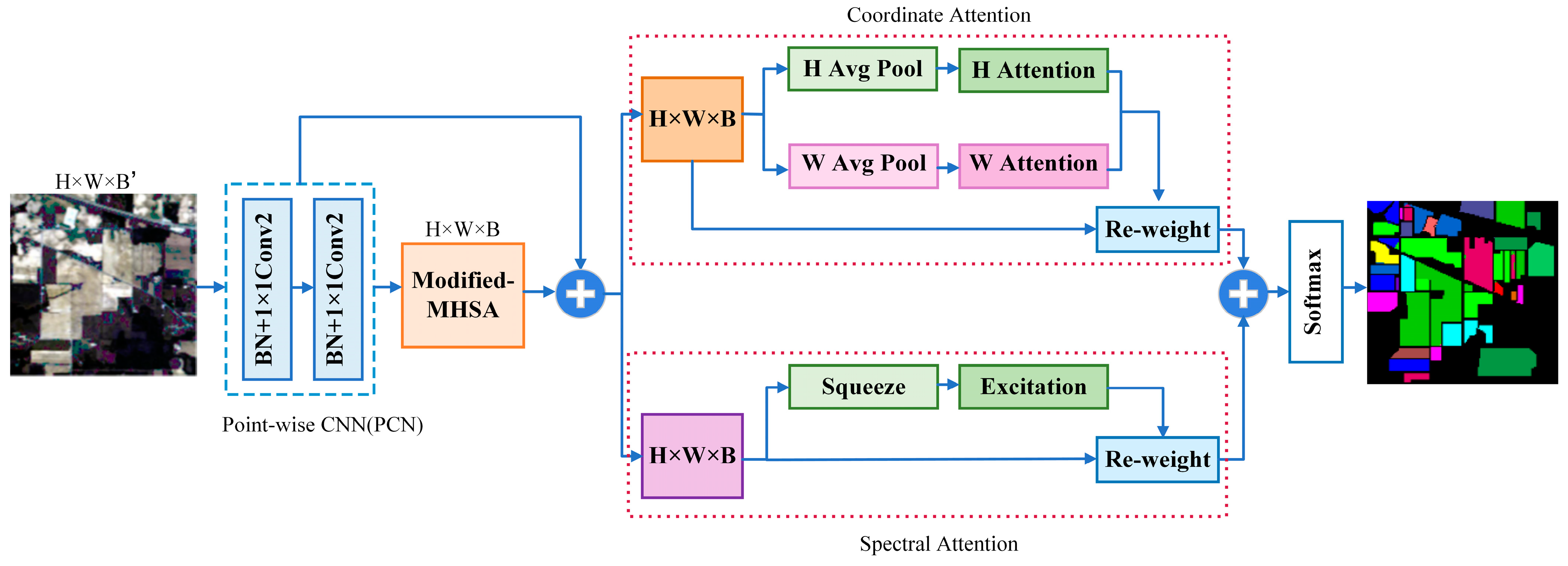
J. Imaging, Free Full-Text
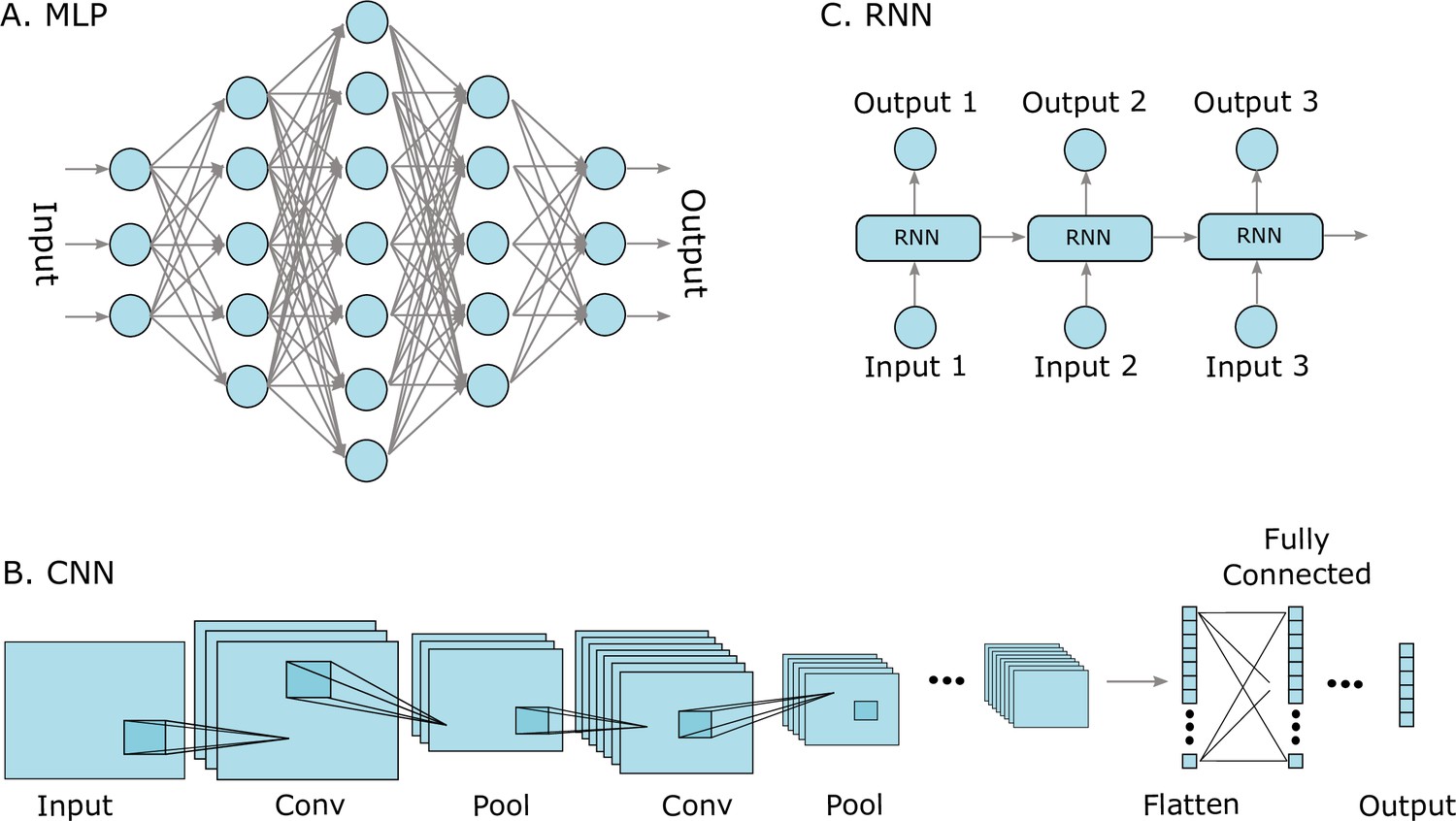
Transformer-based deep learning for predicting protein properties in the life sciences

Understanding the brain with attention: A survey of transformers in brain sciences - Chen - 2023 - Brain‐X - Wiley Online Library
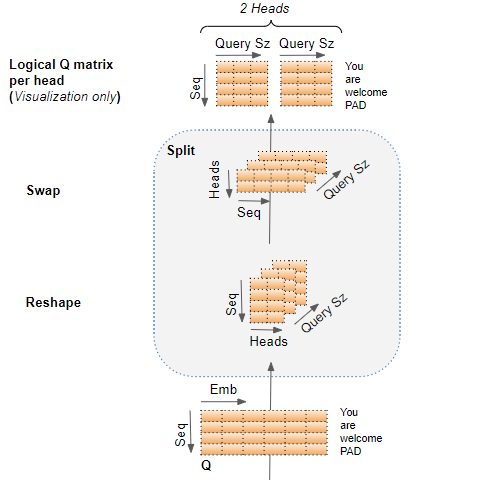
Transformers Explained Visually (Part 3): Multi-head Attention, deep dive, by Ketan Doshi

PDF) Incorporating representation learning and multihead attention to improve biomedical cross-sentence n-ary relation extraction

An example of Multi-head Attention
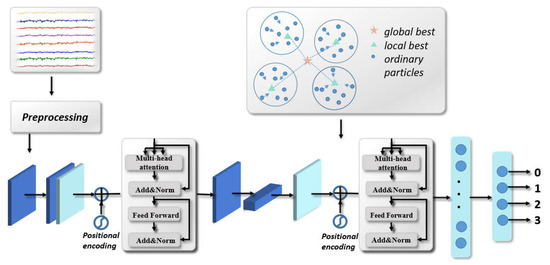
Bioengineering, Free Full-Text
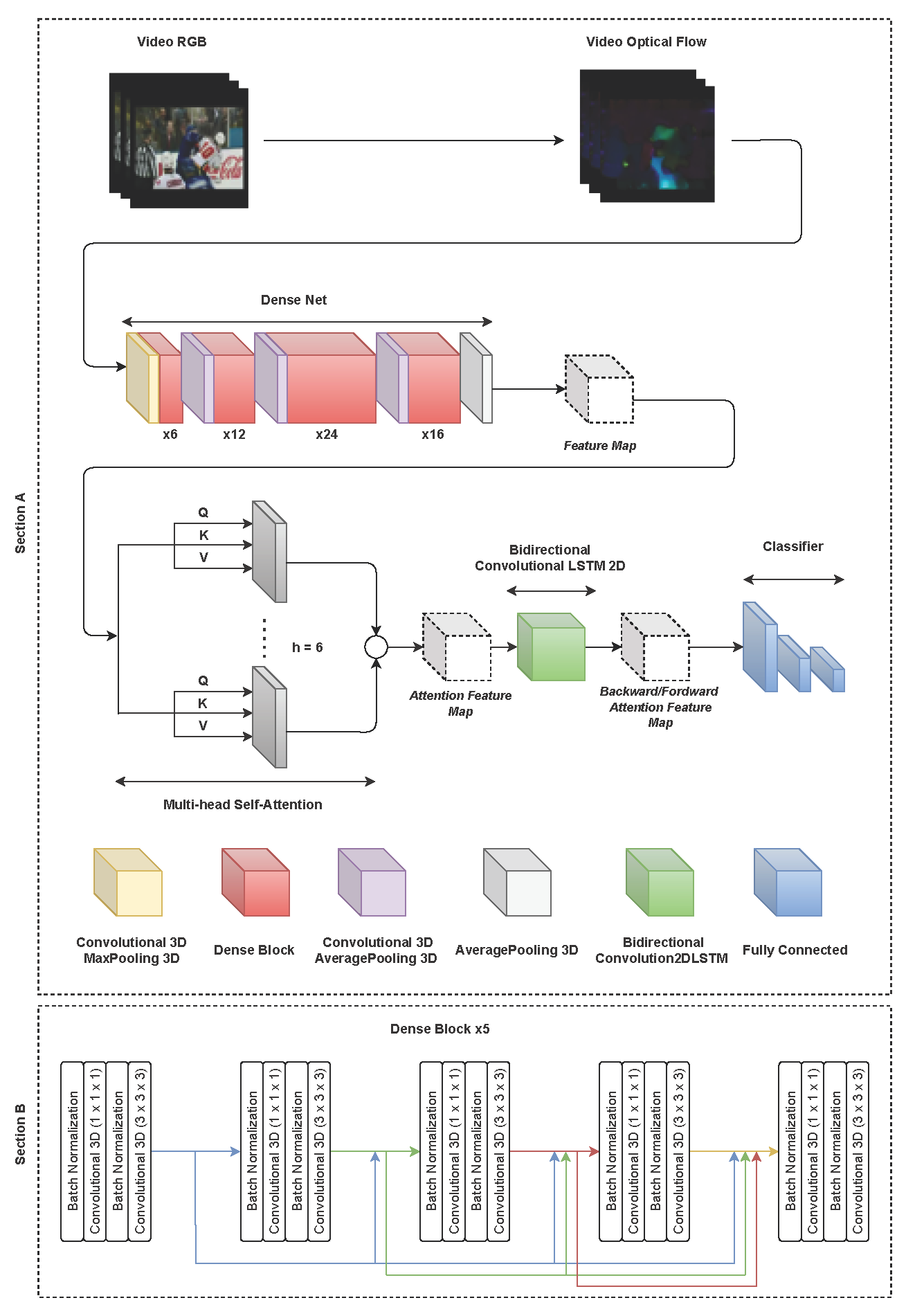
Electronics, Free Full-Text

PDF] Multi-Head Attention: Collaborate Instead of Concatenate

PDF] Informative Language Representation Learning for Massively Multilingual Neural Machine Translation
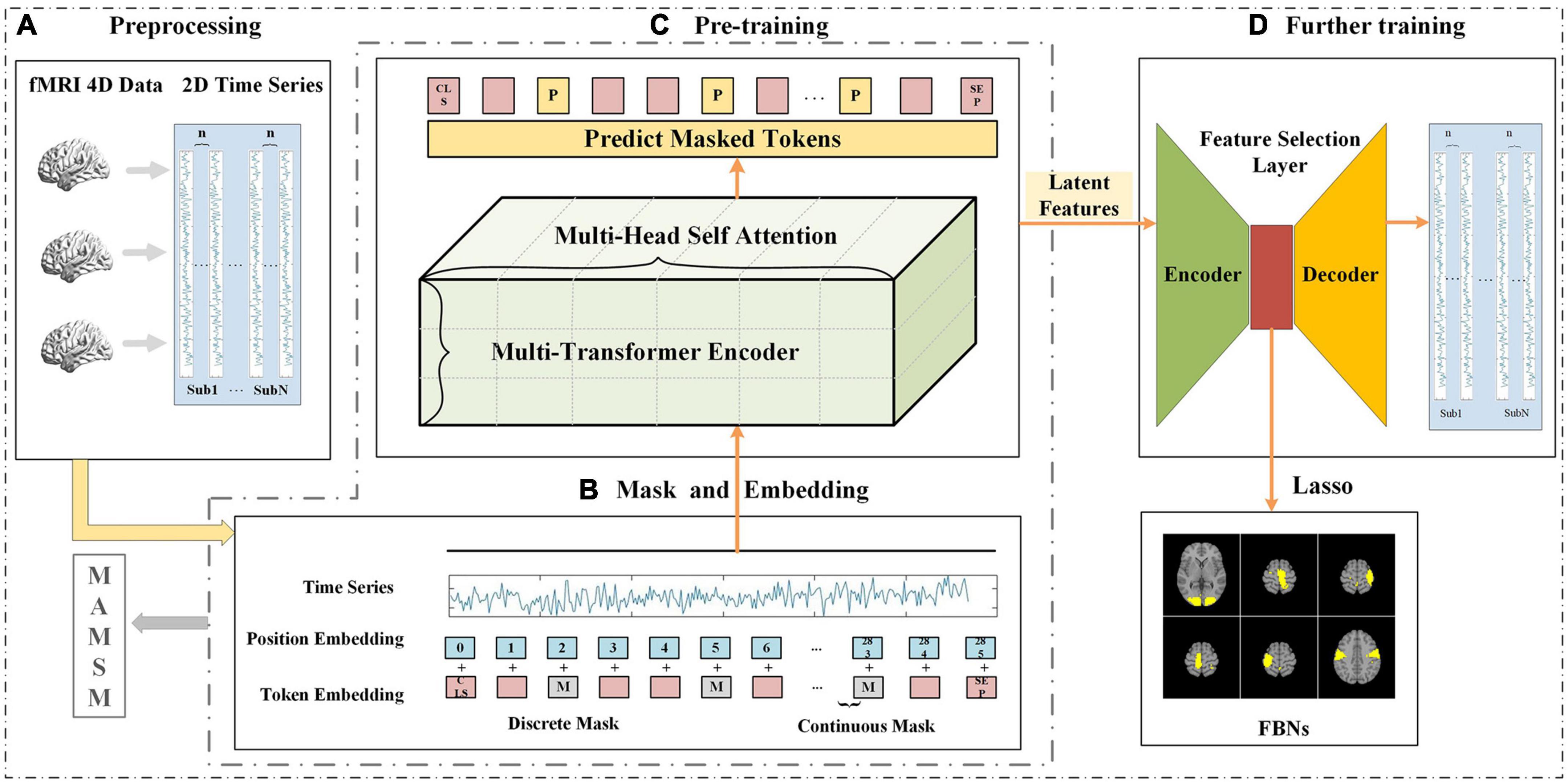
Frontiers Multi-head attention-based masked sequence model for mapping functional brain networks
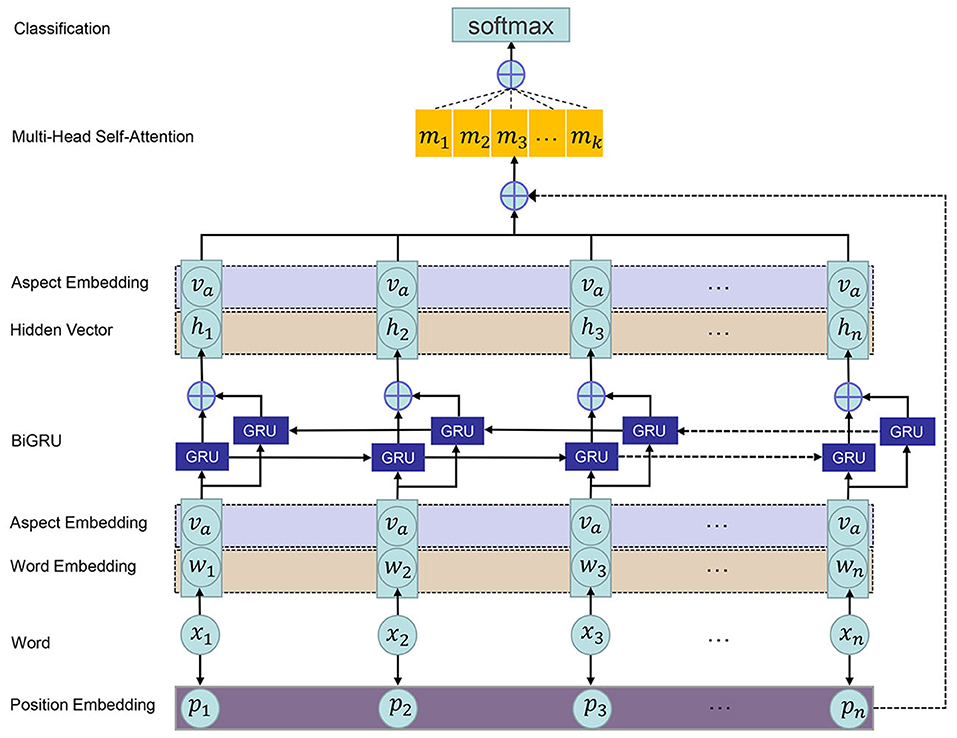
Frontiers Position-Enhanced Multi-Head Self-Attention Based Bidirectional Gated Recurrent Unit for Aspect-Level Sentiment Classification
de
por adulto (o preço varia de acordo com o tamanho do grupo)